Damian Kaliroff, Guy Gilboa, arXiv
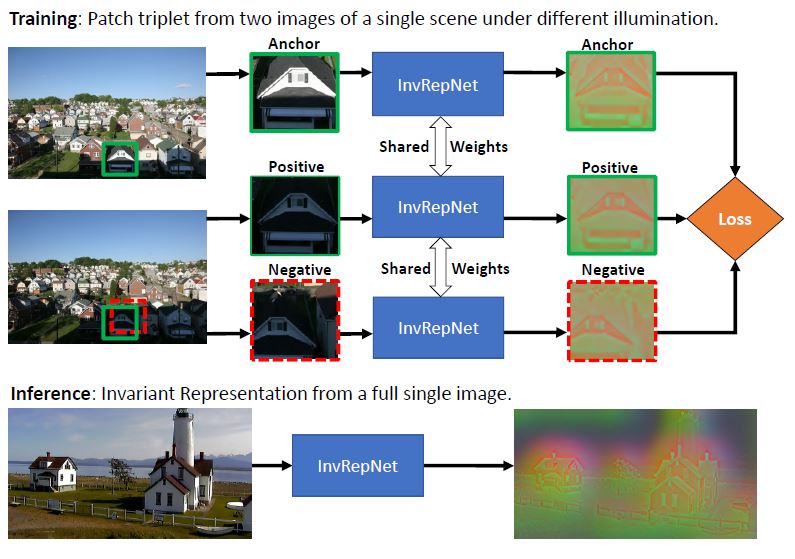
We propose a new and completely data-driven approach for generating an unconstrained illumination invariant representation of images. Our method trains a
neural network with a specialized triplet loss designed to emphasize actual scene
changes while downplaying changes in illumination. For this purpose we use the
BigTime image dataset, which contains static scenes acquired at different times.
We analyze the attributes of our representation, and show that it improves patch
matching and rigid registration over state-of-the-art illumination invariant representations.
We point out that the utility of our method is not restricted to handling
illumination invariance, and that it may be applied for generating representations
which are invariant to general types of nuisance, undesired, image variants.