Had a great time in Denver paresenting 3 papers at CVPR with Omer, Harel, Chen (+Sara), Roy and Yossi.
We had great discussions and the topics seemed to be well received.





Had a great time in Denver paresenting 3 papers at CVPR with Omer, Harel, Chen (+Sara), Roy and Yossi.
We had great discussions and the topics seemed to be well received.

It was great being in Boston and New York. I have visited CSAIL at MIT , Kempner AI Institute at Harvard and finally the Flatiron Institute (Neuroscience Dept) at NYC, headed by Prof. Simoncelli.
In all places I gave a talk related to our recent works on the represention and embedding of foundation models, see abstract below.
I had great conversations with excellent and thoughtfool people. Thanks for the hospitality of Tamr Rott-Shaham (MIT), Yonatan Belinkov (Harvard) and Guy Ohayon (Flatiron) who were very kind and helpful organizing the visits.
Abstract of talk:
How to Encode World Knowledge?
Foundation models are a key platform which implicitly encodes world knowledge. In this talk we first focus on vision-language models, such as CLIP, and investigate their geometric behavior and logic behind the high-dimensional feature encoding. For instance, we find that as image or text become more rare and distinct they are encoded further from the center of the embedding. We explain why InfoNCE loss leads to that behavior. We also find out empirically that each modality can be well modeled statistically as admitting a multivariate Gaussian distribution. This finding is then proved formally, where it is shown that InfoNCE asymptotically induces Gaussian distribution. Finally, we connect two major image foundation models – encoders and generators, through a universal normal embedding hypothesis. A surprising consequence of this hypothesis is demonstrated, where generative diffusion “noise” contains semantic data which can be accessed by linear probing for either classification or editing. This talk is based on 6 recent papers in the group published at ICML 2025, ICLR 2026 and CVPR 2026.
Some pics








Hodaya Krakover, Meir Yossef Levi, Eyal Gofer and Guy Gilboa
ECCV 2026.
Abstract
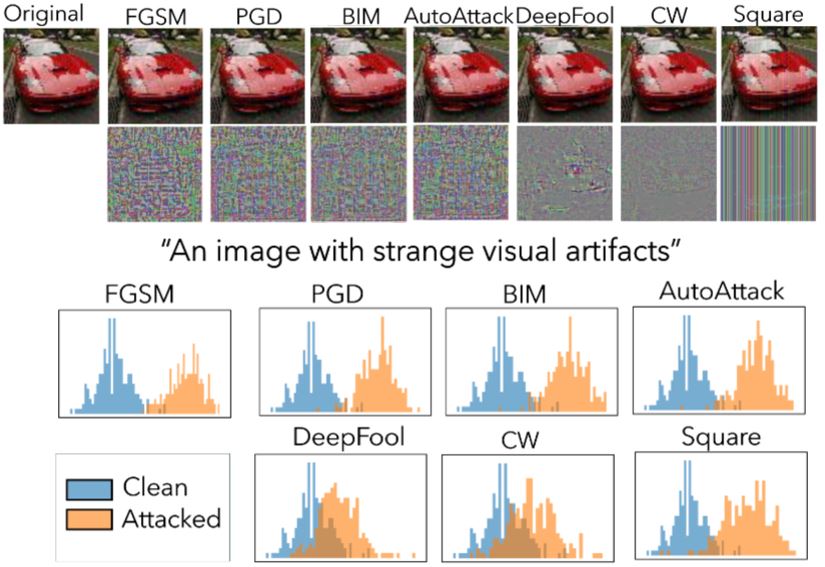
Adversarial attacks pose a challenge to the reliability of deep learning models, motivating effective detection methods. Existing techniques often rely on attack-specific assumptions, access to adversarial samples, or knowledge of the underlying classifier (white-box). We propose $A^4D$ (Attack- and Architecture-Agnostic Adversarial Detector), a completely black-box, zero-shot adversarial attack detection framework that utilizes prompt-based similarity scores derived from CLIP. To the best of our knowledge this is the first attempt to utilize CLIP for such a task.
The method is based on two key observations: (i) CLIP is sensitive even to small imperceptible non-semantic perturbations; (ii) The shift in CLIP embedding space is not arbitrary and can be used as a robust attack indicator.
Experiments across multiple attacks, datasets and classifiers validate that $A^4D$ achieves SOTA detection results in the attack-agnostic and classifier-agnostic setting.

We now have a few open places in the group for excellent MSc and PhD students.
We would like to extend our research on the topics of foundation models representation and the embedding of knwoledge in AI. This involves both deep theoretical understanding and new ideas for applications in image processing and computer vision. For more background on our work so far in these directions see our ICML 2025, ICLR 2026, CVPR 2026 papers.
We also have a separate project on advanced MRI acquisition (jointly with Efrat Shimron).
Requirements
For the MRI project: knowledge in optimization and in MRI are an advantage.
To apply, please email me: guy.gilboa@ee.technion.ac.il
C. Tasker, R. Betser, E. Gofer, M-Y Levi, G. Gilboa, CVPR 2026.
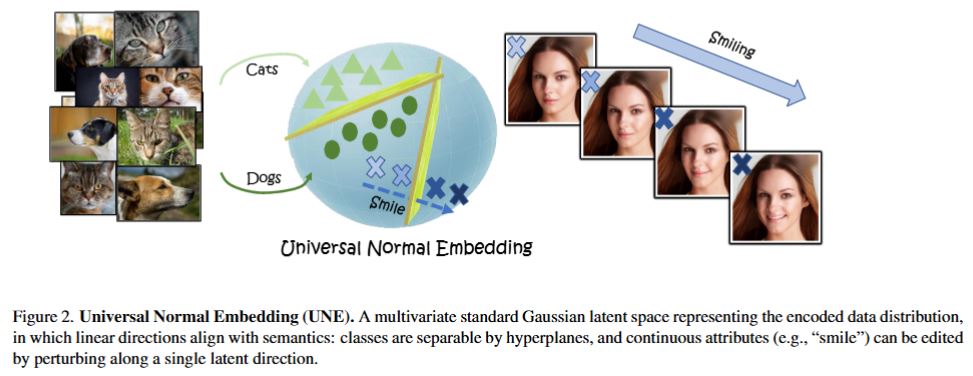
Generative models and vision encoders have largely advanced on separate tracks, optimized for different goals and grounded in different mathematical principles. Yet, they share a fundamental property: latent space Gaussianity. Generative models map Gaussian noise to images, while encoders map images to semantic embeddings whose coordinates empirically behave as Gaussian. We hypothesize that both are views of a shared latent source, the \emph{Universal Normal Embedding (UNE)}: an approximately Gaussian latent space from which encoder embeddings and DDIM-inverted noise arise as noisy linear projections. To test our hypothesis, we introduce \emph{NoiseZoo}, a dataset of per-image latents comprising DDIM-inverted diffusion noise and matching encoder representations (CLIP, DINO). On CelebA, linear probes in both spaces yield strong, aligned attribute predictions, indicating that generative noise encodes meaningful semantics along linear directions. These directions further enable faithful, controllable edits (e.g., smile, gender, age) without architectural changes, where simple orthogonalization mitigates spurious entanglements. Taken together, our results provide empirical support for the UNE hypothesis and reveal a shared Gaussian-like latent geometry that concretely links encoding and generation.
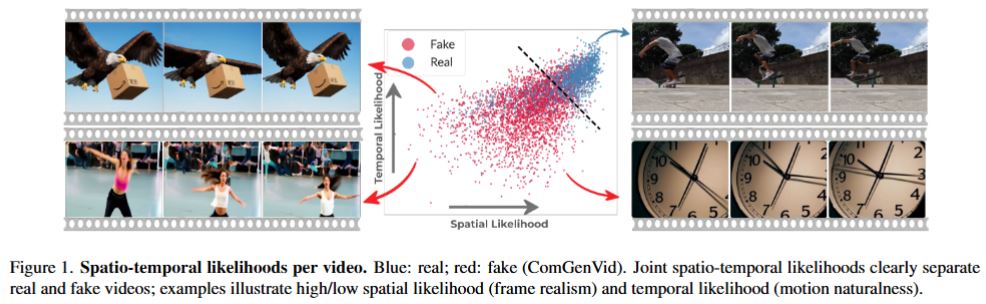
O. Ben Hayun, R. Betser, M-Y Levi, L. Kassel, G. Gilboa, CVPR 2026.
Following major advances in text and image generation, the video domain has surged, producing highly realistic and controllable sequences that transform creative workflows. Along with this progress, these models also raise serious concerns about misinformation, making reliable detection of synthetic videos increasingly crucial. Image-based detectors are fundamentally limited because they operate per frame and ignore temporal dynamics, while supervised video detectors generalize poorly to unseen generators, a critical drawback given the rapid emergence of new models.These challenges motivate zero-shot approaches, which avoid synthetic data and instead score content against real-data statistics, enabling training-free, model-agnostic detection.
We introduce STALL, a simple, training-free, theoretically justified detector that provides likelihood-based scoring for videos, jointly modeling spatial and temporal evidence within a probabilistic framework. Across two public benchmarks including 20 generative models, STALL consistently outperforms prior image- and video-based baselines. To further test generalization, we curate ComGenVid, a new benchmark featuring state-of-the-art models (Sora and Veo-3), on which STALL demonstrates consistent and robust results.
![]()

H. Yadid, M-Y Levi, R. Betser, G. Gilboa, CVPR 2026
All classifiers, including state-of-the-art vision models, possess invariants, partially rooted in the geometry of their linear mappings. These invariants, which reside in the null-space of the classifier, induce equivalent sets of inputs that map to identical outputs. The semantic content of these invariants remains vague, as existing approaches struggle to provide human-interpretable information. To address this gap, we present \emph{Semantic Interpretation of the Null-space Geometry} (SING), a method that constructs equivalent images, with respect to the network, and assigns semantic interpretations to the available variations. We use a mapping from network features to multi-modal vision language models. This allows us to obtain natural language descriptions and visual examples of the induced semantic shifts. SING can be applied to a single image, uncovering local invariants, or to sets of images, allowing a breadth of statistical analysis at the class and model levels. For example, our method reveals that ResNet50 leaks relevant semantic attributes to the null space, whereas DINO-ViT, a ViT pretrained with self-supervised DINO, is superior in maintaining class semantics across the invariant space.
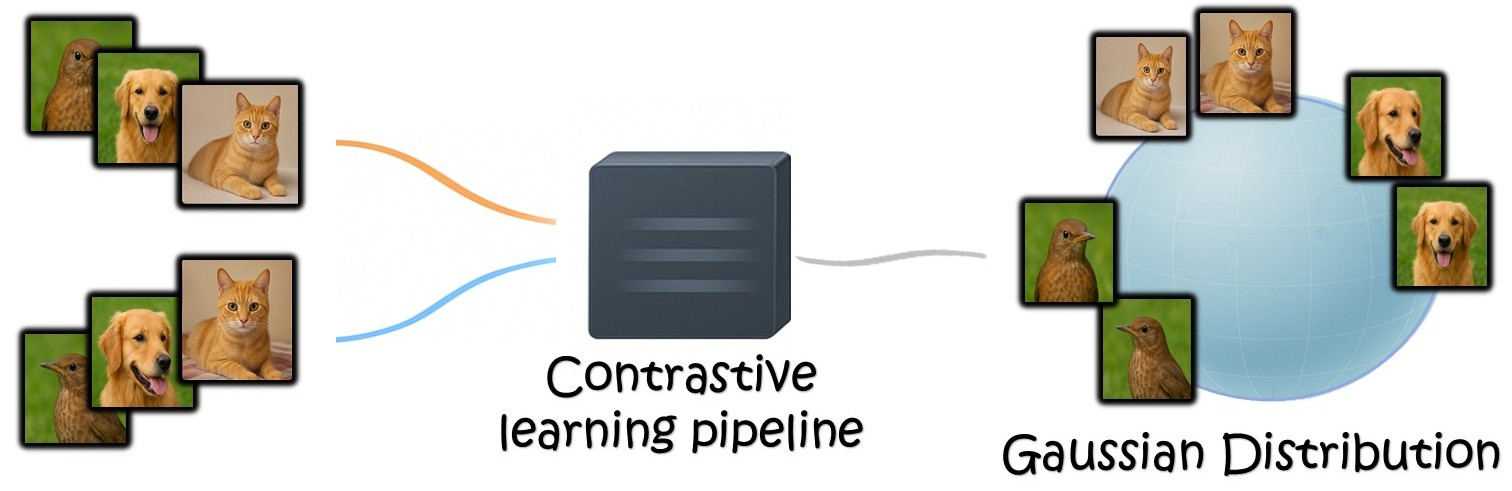
R. Betser, E. Gofer, M-Y Levi, G. Gilboa, ICLR 2026 (oral presentation, top 1.18%)
Contrastive learning has been at the bedrock of unsupervised learning in recent years, allowing training with massive unlabeled data for both task-specific and general (foundation) models. A prototypical loss in contrastive training is InfoNCE and its variants. In this paper we show that the embedding of the features which emerge from InfoNCE training can be well approximated by a multivariate Gaussian distribution. We justify this claim by taking two approaches. First, we show that under certain alignment and concentration assumptions, finite projections of a high dimensional representation approach multivariate Gaussian distribution, as the representation dimensions approach infinity.
Next, under less strict assumptions, we show that adding a small regularization term (which vanishes asymptotically) that promotes low feature norm and high feature entropy, we reach similar asymptotic results. We demonstrate experimentally, in a synthetic setting, CIFAR-10 and on pretrained foundation models, that the features indeed follow almost precise Gaussian distribution. One can use the Gaussian model to easily derive analytic expressions in the representation space and to obtain very useful measures, such as likelihood, data entropy and mutual information. Hence, we expect such theoretical grounding to be very useful in various applications involving contrastive learning.
The Ministy of Innovation, Science and Technology has decided to awarded our group a 3 year grant on the topic “Goemetric and Statistical Models for Zero-shot Detection of Generated Videos and Images”. This is part of the sub-field of exploring new technologies for determining authenticity of digital media.
We have already 2 works on the subject (ICLR 2025, WACV 2026) and plan to pursue this direction with new tools and ideas.
Thanks to Jonathan, Roy, Yossi, Omer and Levi for contributing to the grant application.
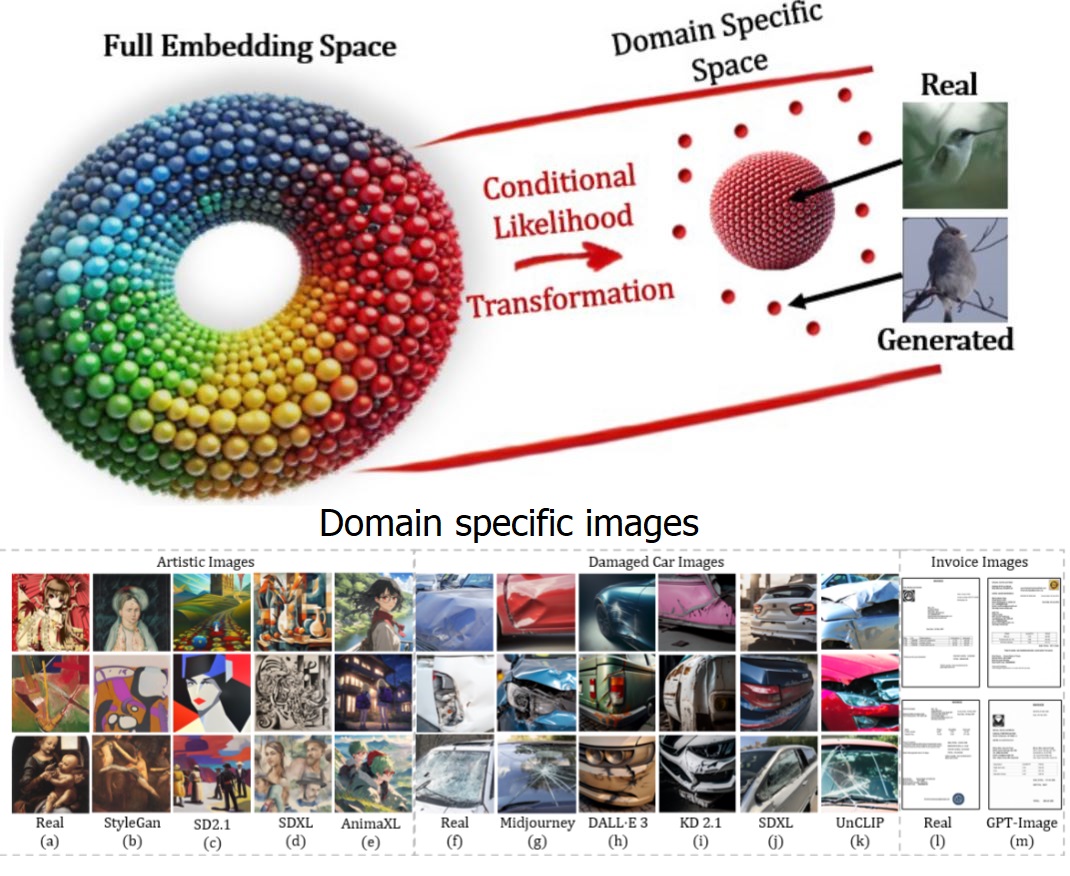
Roy Betser, Omer Hofman, Roman Vainshtein, Guy Gilboa, “General and Domain-Specific Zero-shot Detection of Generated Images via Conditional Likelihood”, accepted to Winter Conference on Applications of Computer Vision (WACV) 2026.
The rapid advancement of generative models, particularly diffusion-based methods, has significantly improved the realism of synthetic images. As new generative models continuously emerge, detecting generated images remains a critical challenge. While fully supervised, and few-shot methods have been proposed, maintaining an updated dataset is time-consuming and challenging. Consequently, zero-shot methods have gained increasing attention in recent years. We find that existing zero-shot methods often struggle to adapt to specific image domains, such as artistic images, limiting their real-world applicability. In this work, we introduce CLIDE, a novel zero-shot detection method based on conditional likelihood approximation. Our approach computes likelihoods conditioned on real images, enabling adaptation across diverse image domains. We extensively evaluate CLIDE, demonstrating state-of-the-art performance on a large-scale general dataset and significantly outperform existing methods in domain-specific cases. These results demonstrate the robustness of our method and underscore the need of broad, domain-aware generalization for the AI-generated image detection task.
![]()