O. Ben Hayun, R. Betser, M-Y Levi, L. Kassel, G. Gilboa, CVPR 2026.
Following major advances in text and image generation, the video domain has surged, producing highly realistic and controllable sequences that transform creative workflows. Along with this progress, these models also raise serious concerns about misinformation, making reliable detection of synthetic videos increasingly crucial. Image-based detectors are fundamentally limited because they operate per frame and ignore temporal dynamics, while supervised video detectors generalize poorly to unseen generators, a critical drawback given the rapid emergence of new models.These challenges motivate zero-shot approaches, which avoid synthetic data and instead score content against real-data statistics, enabling training-free, model-agnostic detection.
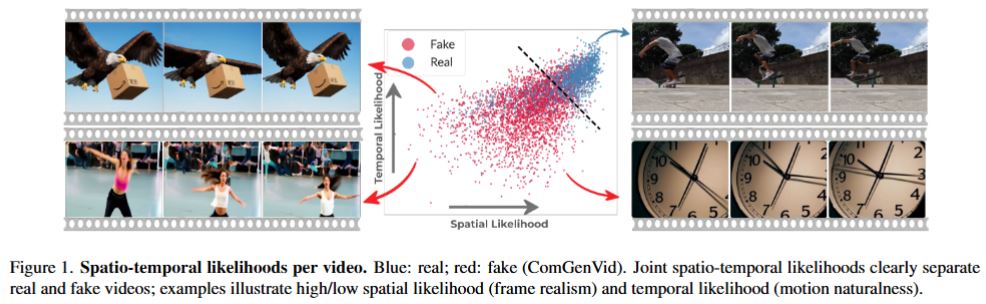
We introduce STALL, a simple, training-free, theoretically justified detector that provides likelihood-based scoring for videos, jointly modeling spatial and temporal evidence within a probabilistic framework. Across two public benchmarks including 20 generative models, STALL consistently outperforms prior image- and video-based baselines. To further test generalization, we curate ComGenVid, a new benchmark featuring state-of-the-art models (Sora and Veo-3), on which STALL demonstrates consistent and robust results.
![]()