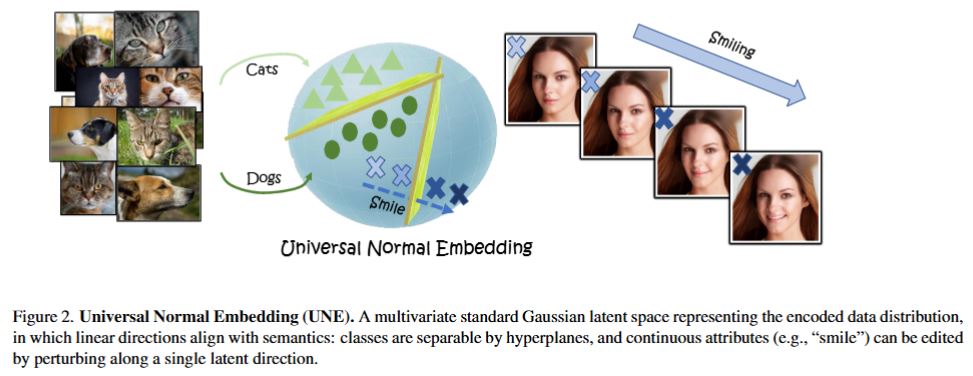
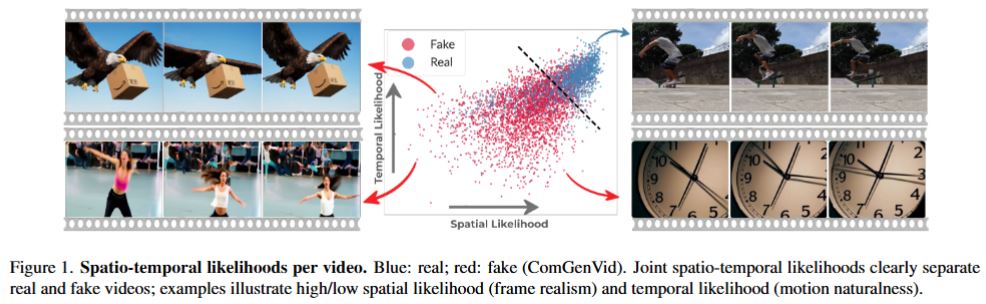
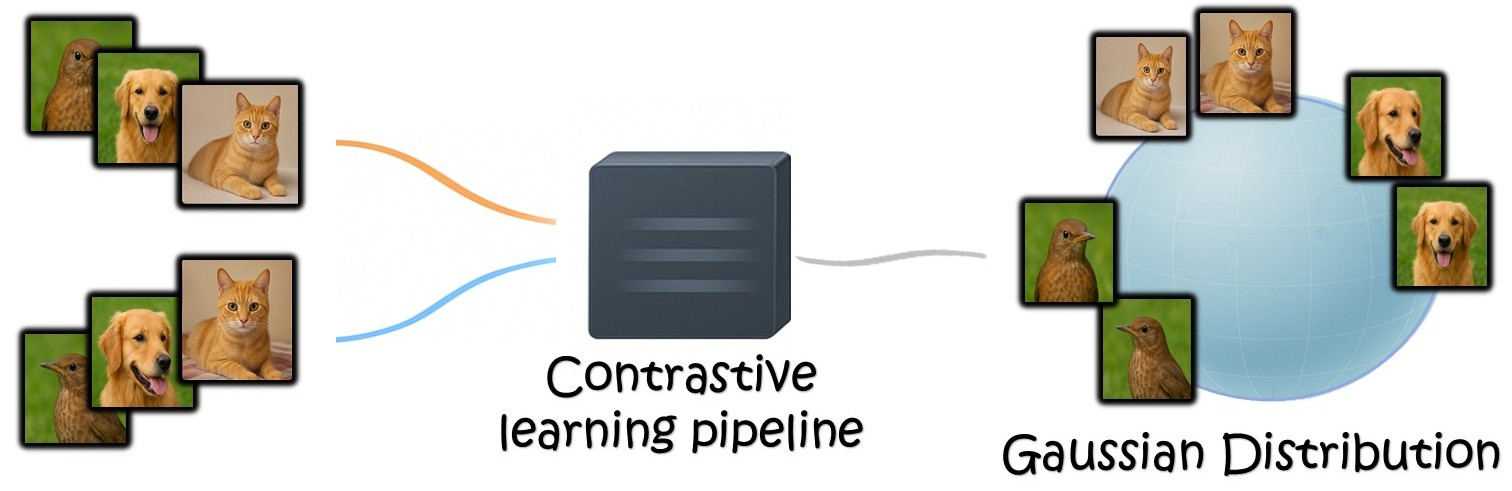
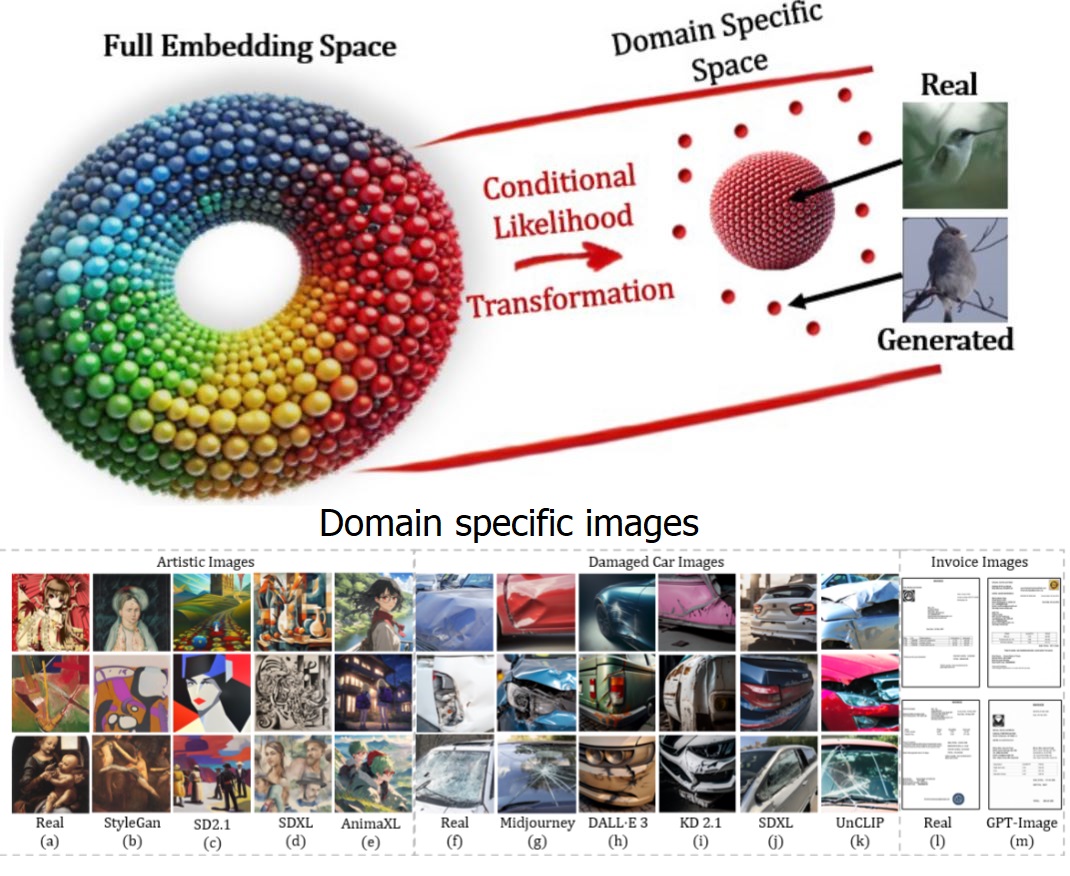
We now have a few open places in the group for excellent MSc and PhD students.
We would like to extend our research on the topics of foundation models representation and the embedding of knwoledge in AI. This involves both deep theoretical understanding and new ideas for applications in image processing and computer vision. For more background on our work so far in these directions see our ICML 2025, ICLR 2026, CVPR 2026 papers.
We also have a separate project on advanced MRI acquisition (jointly with Efrat Shimron).
Requirements
- Excellent ECE students (BSc GPA of 90 and above) with background in signal processing and machine learning.
- Strong mathematical and signal processing skills, esp. in linear algebra, random signals, DSP.
- Good personal skills, ability to work in groups.
For the MRI project: knowledge in optimization and in MRI are an advantage.
To apply, please email me: guy.gilboa@ee.technion.ac.il