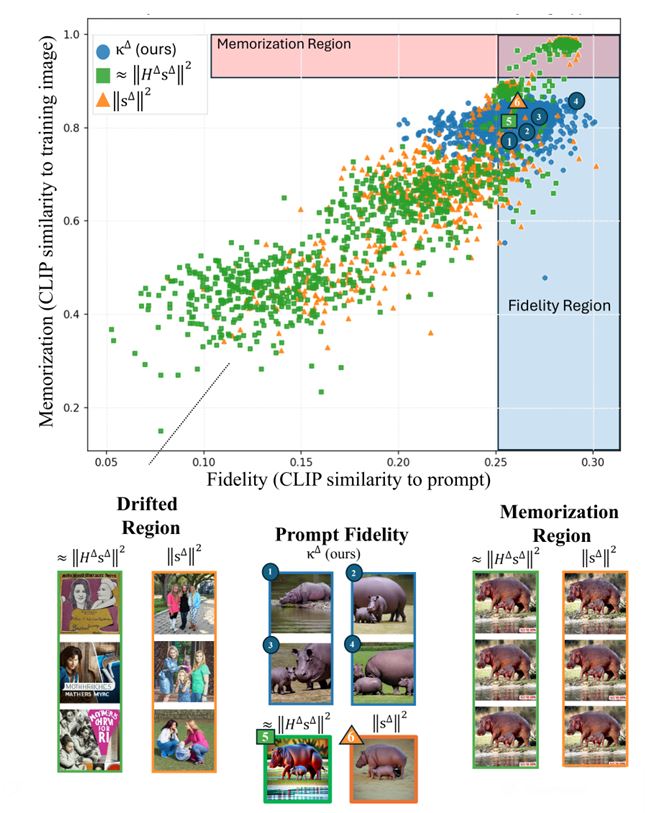
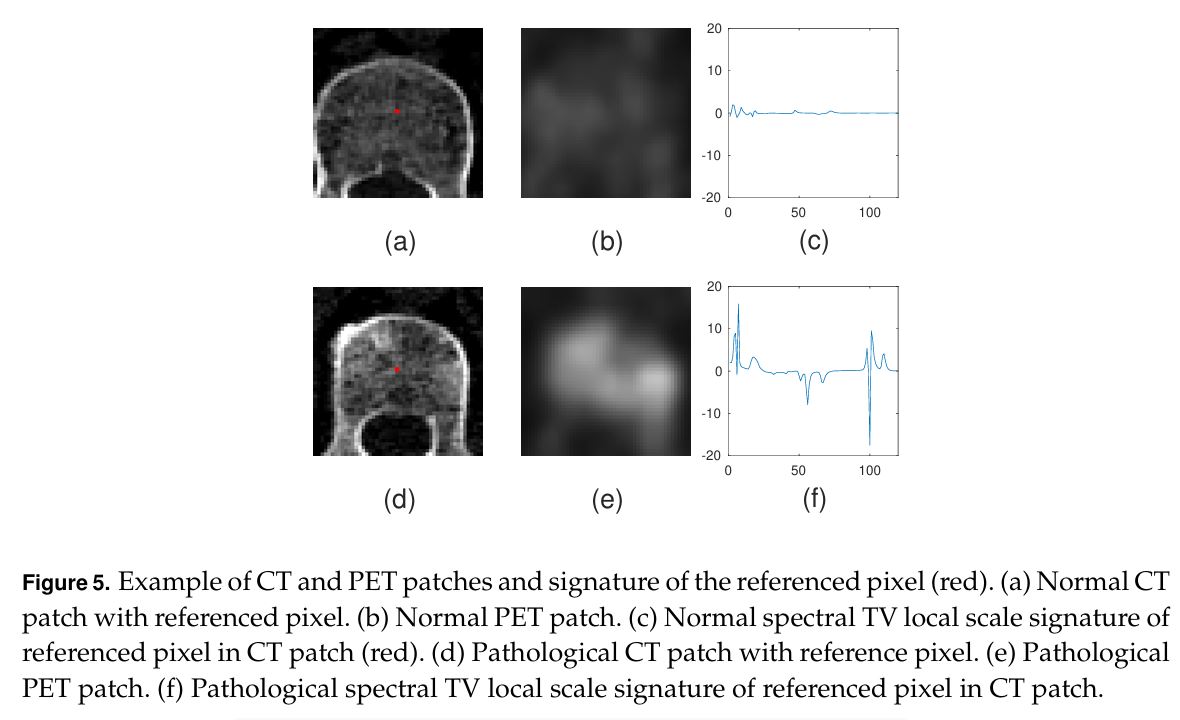
Elnatan Kadar, Guy Gilboa, “DXAI: Explaining Classification by Image Decomposition”, accepted to The Visual Computer 2025.
We propose a new way to explain and to visualize neural network classification through a decomposition-based explainable AI (DXAI). Instead of providing an explanation heatmap, our method yields a decomposition of the image into class-agnostic and class-distinct parts, with respect to the data and chosen classifier. Following a fundamental signal processing paradigm of analysis and synthesis, the original image is the sum of the decomposed parts. We thus obtain a radically different way of explaining classification. The class-agnostic part ideally is composed of all image features which do not posses class information, where the class-distinct part is its complementary. This new visualization can be more helpful and informative in certain scenarios, especially when the attributes are dense, global and additive in nature, for instance, when colors or textures are essential for class distinction.
![]()